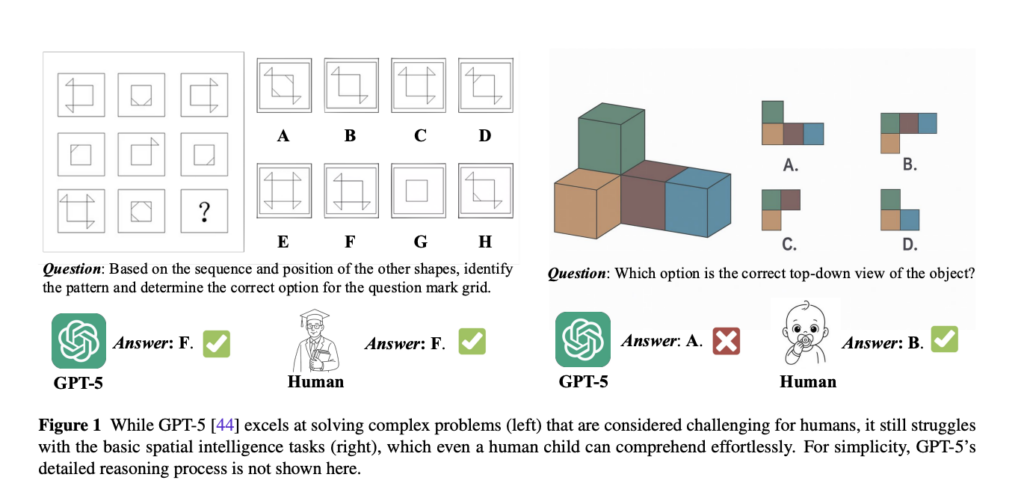
Sztuczna inteligencja (AI) potrafi pisać wiersze, komponować muzykę i prowadzić złożone rozmowy. Jednak zapytajmy ją o coś, co dla pięciolatka jest banalnie proste – na przykład, jak będzie wyglądał stos klocków widziany z góry – a najpotężniejsze modele często zawodzą. Ta fundamentalna słabość, zwana inteligencją przestrzenną, jest jedną z ostatnich i najważniejszych barier na drodze do stworzenia prawdziwej sztucznej inteligencji ogólnej (AGI). Bez zdolności do rozumienia i wnioskowania na temat fizycznego świata, AI pozostanie zamknięta w cyfrowej sferze, niezdolna do pełnej interakcji z naszą rzeczywistością w robotyce, autonomicznych pojazdach czy zaawansowanej medycynie. Nowe, obszerne badanie oceniające najnowszy model GPT-5 rzuca światło na to, jak blisko – a jednocześnie jak daleko – jesteśmy od przełomu.
Paradoks inteligencji AI: nadludzka w abstrakcji, dziecinna w przestrzeni
Najnowsze badanie empiryczne, przeprowadzone przez naukowców z SenseTime Research i Nanyang Technological University, stawia wprost pytanie: czy GPT-5 osiągnął inteligencję przestrzenną? Analiza, która objęła osiem specjalistycznych benchmarków i pochłonęła moc obliczeniową równą przetworzeniu ponad miliarda tokenów, ujawnia fascynujący paradoks. GPT-5 z łatwością rozwiązuje złożone, abstrakcyjne problemy z sekwencjami wzorów, które sprawiają trudność wielu ludziom. Jednocześnie ten sam model potrafi udzielić błędnej odpowiedzi na proste pytanie o widok obiektu 3D z góry – zadanie intuicyjne nawet dla dziecka.
Ten kontrast pokazuje, że inteligencja przestrzenna to fundamentalnie odrębna zdolność, której nie da się w pełni posiąść jedynie poprzez analizę tekstu i obrazów z internetu. Aby usystematyzować to wyzwanie, badacze zdefiniowali sześć kluczowych filarów, które razem tworzą inteligencję przestrzenną.
Sześć fundamentalnych zdolności inteligencji przestrzennej
Badanie proponuje ujednoliconą taksonomię, która pozwala precyzyjnie mierzyć i porównywać różne aspekty rozumienia przestrzennego. Każda z tych zdolności reprezentuje inny poziom wyzwania dla modeli AI.
| Zdolność | Opis działania | Przykład w realnym świecie |
| Pomiar metryczny (MM) | Szacowanie wymiarów, odległości i głębi na podstawie obrazu 2D. | Ocena, czy szafa zmieści się w danym rogu pokoju. |
| Rekonstrukcja mentalna (MR) | Wnioskowanie o pełnej strukturze obiektu 3D na podstawie ograniczonych widoków. | Wyobrażenie sobie, jak wygląda budynek z tyłu, widząc tylko jego przód. |
| Relacje przestrzenne (SR) | Rozumienie wzajemnego położenia i orientacji obiektów (np. „na lewo od”, „za”). | Opisanie drogi do celu: „za kościołem skręć w prawo”. |
| Przyjmowanie perspektywy (PT) | Wyobrażenie sobie sceny z innego punktu widzenia. | Wyobrażenie sobie, co widzi osoba siedząca naprzeciwko ciebie. |
| Deformacja i składanie (DA) | Rozumowanie na temat zmian kształtu, składania i rozkładania obiektów. | Składanie mebli według instrukcji lub przewidywanie, jak złożyć karton. |
| Złożone rozumowanie (CR) | Koordynacja wielu zdolności przestrzennych w wieloetapowych zadaniach. | Planowanie trasy w nieznanym budynku lub rozwiązywanie złożonej łamigłówki. |
Werdykt dla GPT-5: nowy lider z wyraźnymi ograniczeniami
Wyniki badania są jednoznaczne: GPT-5 ustanawia nowy, najwyższy standard w dziedzinie inteligencji przestrzennej, deklasując poprzednie modele, zarówno zamknięte (jak Gemini 2.5 Pro), jak i te z rodziny open-source. Jednak jego sukces nie jest równomierny we wszystkich sześciu kategoriach.
Obszary sukcesu:
Model osiąga, a w niektórych przypadkach nawet przewyższa, ludzką skuteczność w dwóch fundamentalnych obszarach:
- Pomiar metryczny (MM): GPT-5 potrafi z dużą dokładnością oszacować wymiary obiektów czy odległości na zdjęciach, prawdopodobnie dzięki solidnym wzorcom geometrycznym nabytym podczas treningu na ogromnych zbiorach danych.
- Relacje przestrzenne (SR): Model doskonale radzi sobie z prostymi zadaniami polegającymi na określaniu wzajemnego położenia obiektów.
Obszary, w których AI wciąż zawodzi:
Pomimo postępów, GPT-5 wciąż znacząco ustępuje człowiekowi w czterech bardziej zaawansowanych i wymagających zintegrowanych zdolnościach:
- Rekonstrukcja mentalna (MR): Chociaż model po raz pierwszy pokazał zdolność do poprawnej rekonstrukcji obiektu z kilku widoków, nadal popełnia błędy w prostych zadaniach, które dla ludzi są oczywiste.
- Przyjmowanie perspektywy (PT): To jedna z największych słabości. Modele mają ogromny problem z wyobrażeniem sobie sceny z innego punktu widzenia, zwłaszcza gdy widoki te mało się na siebie nakładają.
- Deformacja i składanie (DA): Ten obszar pozostaje krytyczną słabością. GPT-5 zawodzi w zadaniach wymagających mentalnego składania siatki 2D w sześcian 3D czy rozumowania na temat transformacji strukturalnych.
- Złożone rozumowanie (CR): Model potrafi rozpoznać widoczne elementy, ale nie jest w stanie wnioskować o istnieniu obiektów ukrytych (np. klocków stanowiących podporę dla innych), co jest podstawą rozumowania przestrzennego.
Co ciekawe, badanie wykazało, że w przypadku najtrudniejszych zadań (szczególnie PT i DA) przewaga modeli zamkniętych, takich jak GPT-5, nad najlepszymi modelami open-source maleje. Oznacza to, że samo zwiększanie skali modelu nie wystarczy do pokonania tych barier.
Co to oznacza dla przyszłości AI?
Analiza GPT-5 pokazuje, że osiągnęliśmy punkt, w którym dalszy postęp w inteligencji przestrzennej nie będzie wynikał z prostego skalowania istniejących architektur. Droga do prawdziwego rozumienia świata fizycznego wymaga nowych podejść metodologicznych. Być może modele przyszłości będą musiały uczyć się nie tylko z pasywnych obrazów, ale także poprzez interakcję w symulowanych środowiskach 3D, aby nabyć intuicji fizycznej, która dla nas jest naturalna. Badanie to stanowi cenny drogowskaz, precyzyjnie wskazując, gdzie leżą największe wyzwania.
Najczęściej zadawane pytania (FAQ)
- Dlaczego rozumienie przestrzenne jest tak trudne dla AI?
Ludzie rozwijają inteligencję przestrzenną poprzez fizyczną interakcję ze światem od najmłodszych lat – dotykamy przedmiotów, poruszamy się, uczymy się grawitacji i perspektywy. Modele AI uczą się głównie na podstawie dwuwymiarowych pikseli i tekstu, co nie daje im tego „ucieleśnionego” zrozumienia praw fizyki i geometrii. - Czym w praktyce różni się rekonstrukcja mentalna od przyjmowania perspektywy?
Rekonstrukcja mentalna polega na zbudowaniu w „umyśle” kompletnego modelu 3D obiektu, np. na podstawie rysunków technicznych. Przyjmowanie perspektywy to bardziej dynamiczna umiejętność wyobrażenia sobie, jak istniejąca scena wyglądałaby z innego miejsca, bez konieczności tworzenia idealnego modelu każdego obiektu. - Czy to oznacza, że powinniśmy przestać rozwijać obecne modele wielomodalne?
Absolutnie nie. Badanie pokazuje, że obecne modele osiągnęły imponujące zdolności w podstawowych zadaniach. Stanowi ono jednak wezwanie dla społeczności naukowej do skupienia się na nowych architekturach i metodach treningu, które będą specyficznie ukierunkowane na przezwyciężenie zidentyfikowanych słabości. - Jakie konkretne zastosowania odblokuje AI z rozwiniętą inteligencją przestrzenną?
Robot domowy, który potrafi nawigować w zagraconym pokoju i składać pranie. Asystent chirurgiczny, który rozumie trójwymiarową anatomię pacjenta na podstawie skanów 2D. Systemy do projektowania architektonicznego, które potrafią inteligentnie optymalizować przestrzeń. To tylko kilka przykładów. - Dlaczego data publikacji badania to sierpień 2025?
Jest to data fikcyjna, użyta w materiale źródłowym, prawdopodobnie w celu stworzenia realistycznego scenariusza badania hipotetycznego, przyszłego modelu GPT-5. Należy traktować to jako element ćwiczenia analitycznego, a nie realną prognozę.